
Emergency Medicine
Session: Emergency Medicine 13
 photo")
Jessica K. Creedon, MD (she/her/hers)
Assistant in Medicine
Boston Children's Hospital
Dover, Massachusetts, United States
.png) Pediatric emergency medicine attending ratings of ChatGPT-generated neurology consults compared to in-person pediatric neurology consults. Ratings were based on a 10-point Likert scale across five domains: accuracy, completeness, efficiency, readability, and overall quality. ChatGPT output was rated highest in the domains of efficiency and readability (n = 14).
Pediatric emergency medicine attending ratings of ChatGPT-generated neurology consults compared to in-person pediatric neurology consults. Ratings were based on a 10-point Likert scale across five domains: accuracy, completeness, efficiency, readability, and overall quality. ChatGPT output was rated highest in the domains of efficiency and readability (n = 14). 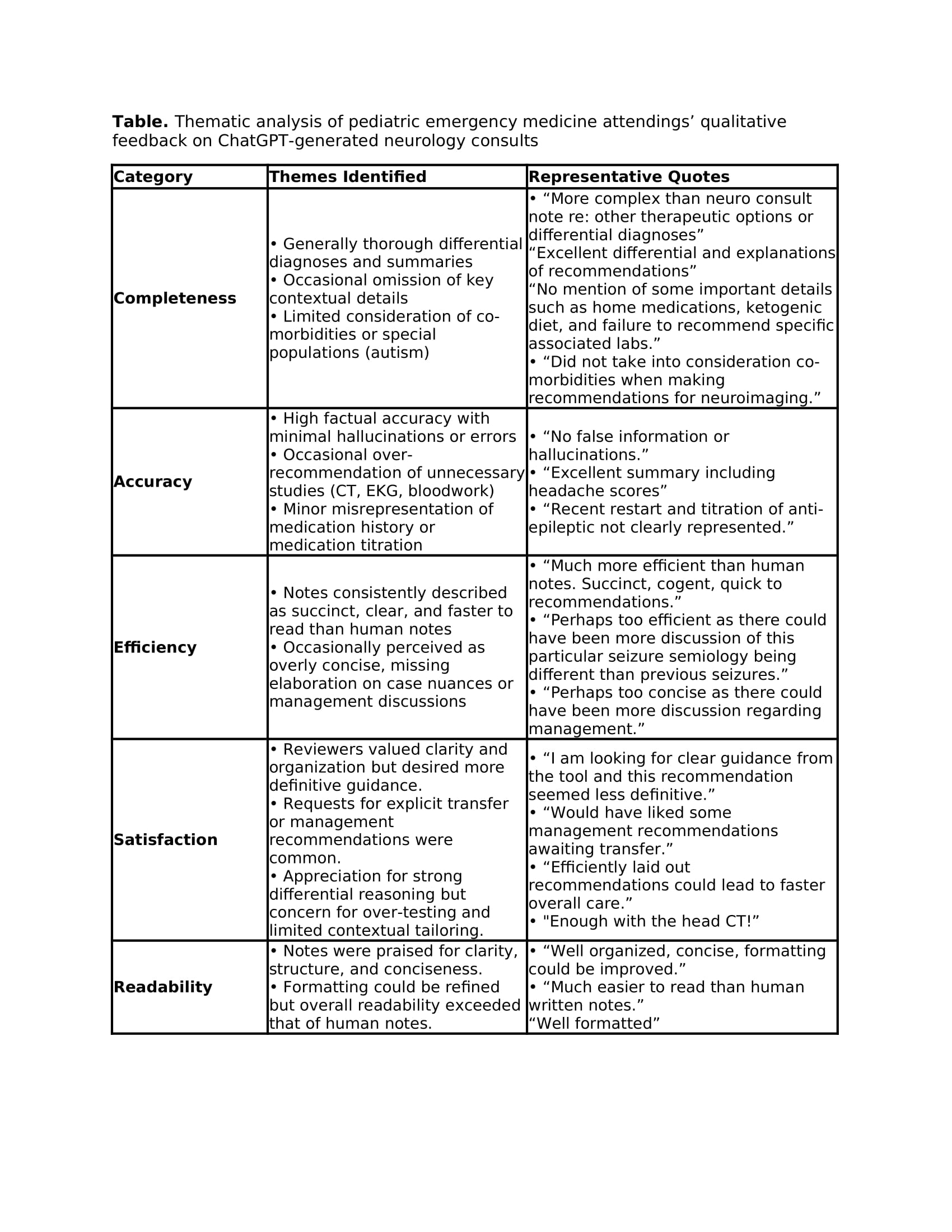 Thematic analysis of pediatric emergency medicine attendings' qualitative feedback on ChatGPT-generated neurology consults, highlighting key themes, limitations, and opportunities for improving LLM use in pediatric neurologic emergencies.
Thematic analysis of pediatric emergency medicine attendings' qualitative feedback on ChatGPT-generated neurology consults, highlighting key themes, limitations, and opportunities for improving LLM use in pediatric neurologic emergencies.