766 - Predicting Neonatal Outcomes in the Presence of Heterogeneity: Lessons Learned from the Neocosur Network
Friday, April 24, 2026
5:30pm - 8:00pm ET
Publication Number: 1742.766
Cecilia Cocucci, Hospital Universitario Austral, Buenos Aires, Buenos Aires, Argentina; Sebastian Camerlingo, Austral, Buenos Aires, Buenos Aires, Argentina; Gabriel Musante, Hospital Universitario Austral, Pilar, Buenos Aires, Argentina
Neonatologist - Assistant Professor Biostatistics Hospital Universitario Austral Buenos Aires, Buenos Aires, Argentina
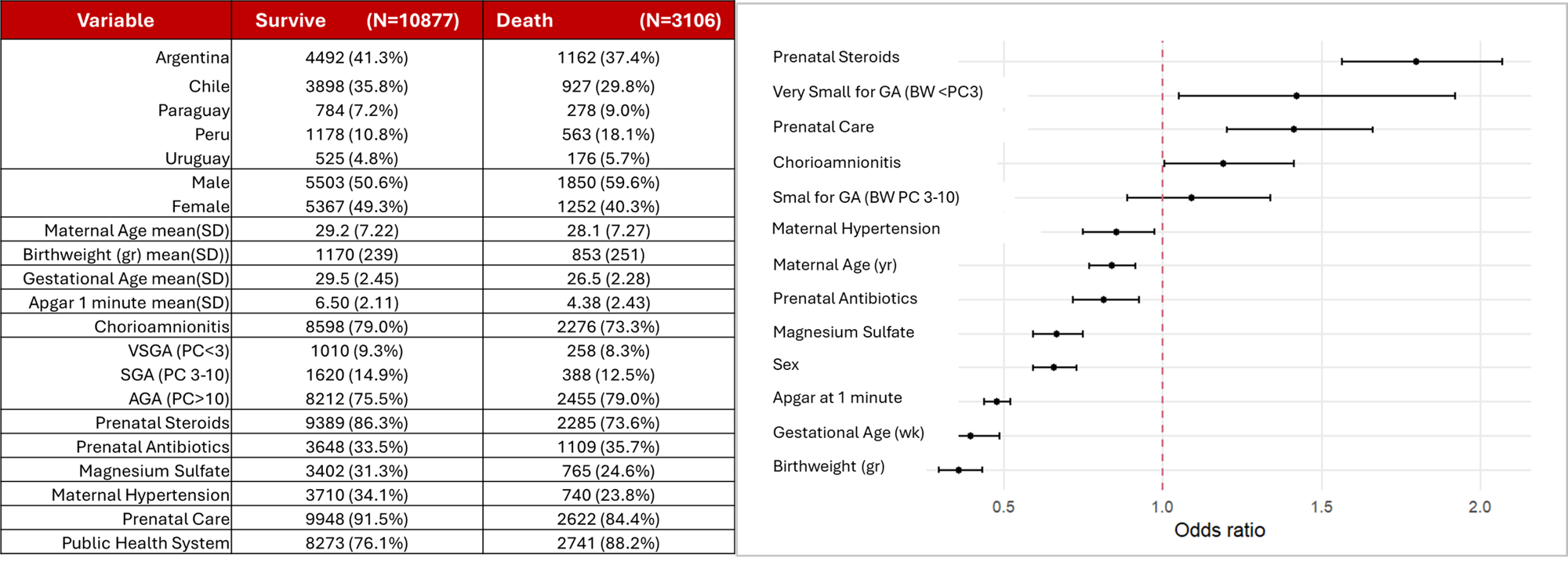
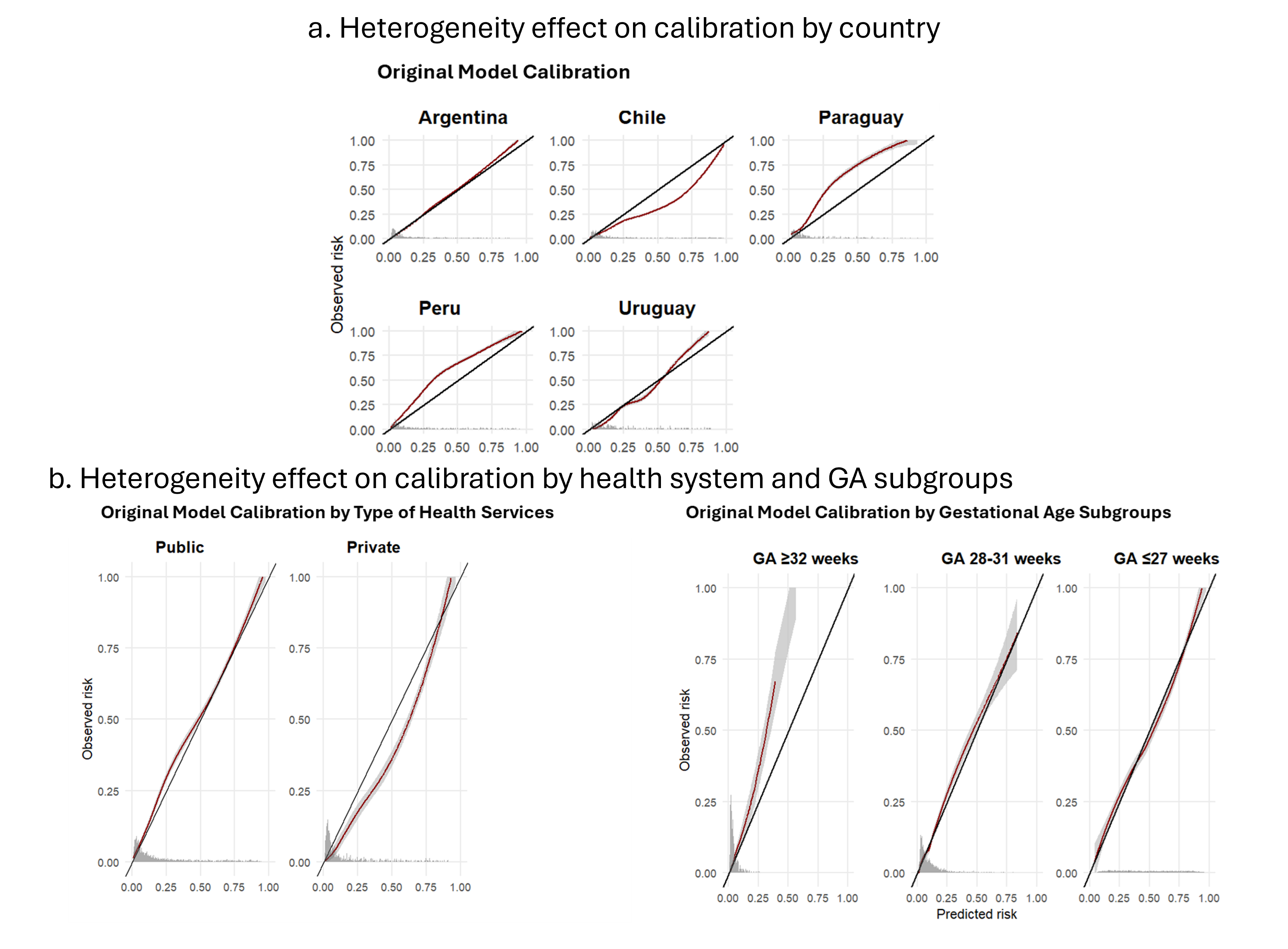
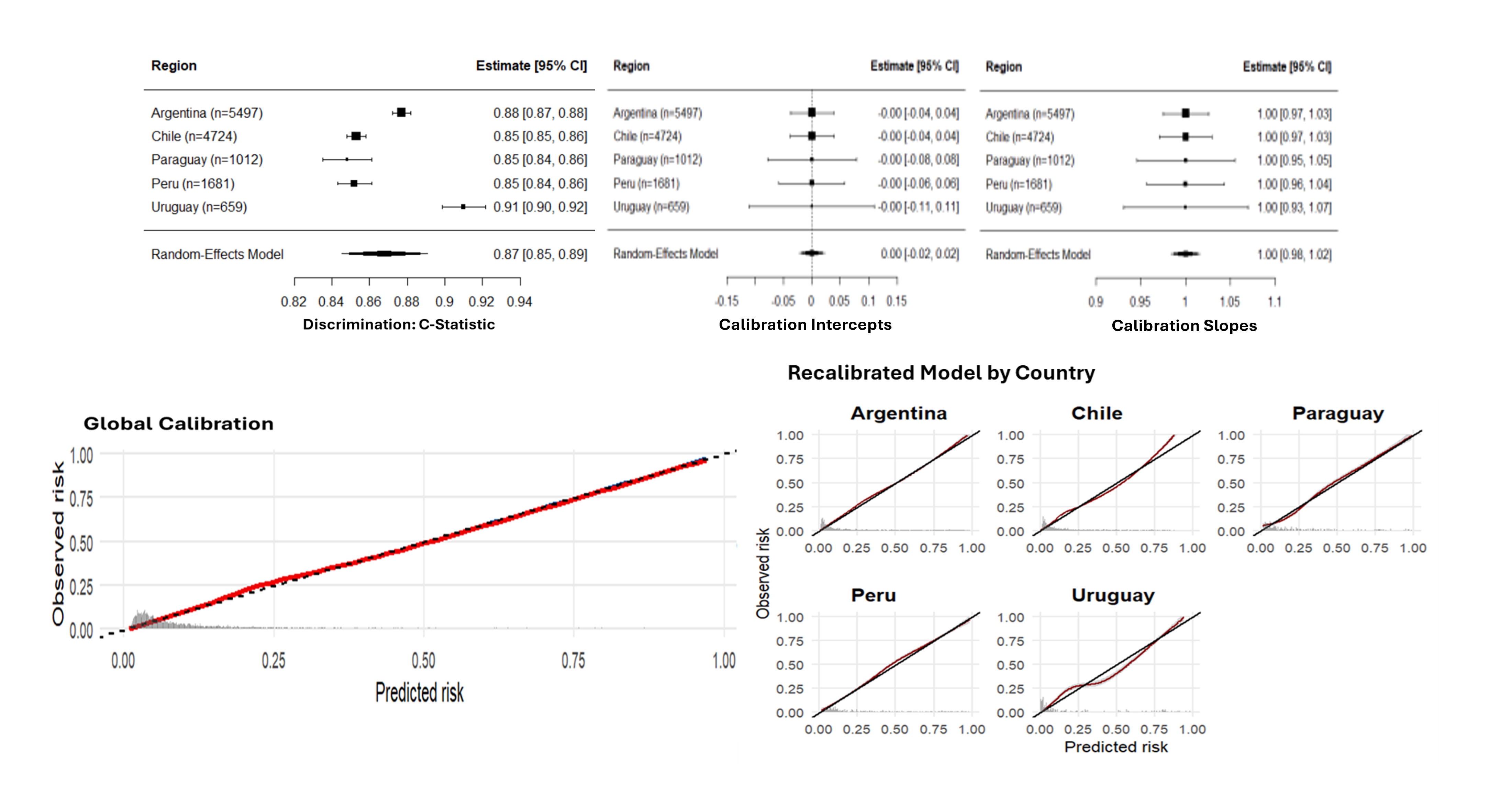
Background: In neonatal networks, between-center heterogeneity arises from both measurable case-mix differences and unmeasurable center-specific factors (practices, resources, organizational culture). Quality improvement (QI) initiatives rely on risk-adjusted models to benchmark NICU performance. While discrimination with AUC is routinely reported, calibration is rarely assessed, especially across subgroups. This masks a critical problem: models with excellent overall performance may systematically over- or under-predict mortality in specific populations, generating biased quality metrics and limiting center comparisons. In heterogeneous networks, global performance can conceal subgroup miscalibration, affecting both benchmarking fairness and individual risk assessment Objective: To evaluate how network heterogeneity affects the validity of mortality predictions and quality comparisons across subgroups, and to illustrate its implications for bedside counseling and benchmarking in a multinational NICU network Design/Methods: We analyzed 13,983 VLBW infants (GA 23-32 weeks) born in 31 centers of the Neocosur Network (Argentina, Chile, Paraguay, Peru, Uruguay) from 2011-2023. Using only perinatal variables, we developed a LASSO logistic regression model to predict in-hospital death. Performance was evaluated using AUC, calibration intercept, and slope and heterogeneity via internal-external cross-validation (leave-one-country-out). Calibration was assessed globally and stratified by country, health system type, and GA categories. When miscalibrated, linear recalibration was applied Results: LASSO retained 12 predictors. The model showed excellent discrimination (AUC 0.86-0.89) and near-perfect global calibration after bootstrap validation (C=0.861; slope=0.995; intercept=-0.006). However, subgroup calibration revealed systematic bias: calibration-in-the-large ranged from -0.75 in Chile to +0.75 in Paraguay, and from -0.57 in public to +0.11 in private centers, with underprediction in extremely preterm infants and overprediction in more mature ones (Figure). After country-specific linear recalibration intercept reached ~0 and slope ~1 while AUC remained stable (0.86 [0.85-0.87])
Conclusion(s): Despite excellent global performance, mortality predictions showed substantial miscalibration across countries, center types, and gestational ages, potentially misclassifying center quality. In heterogeneous networks, discrimination metrics alone are insufficient for fair benchmarking. Networks should assess and report subgroup-specific calibration before comparing centers or implementing QI initiatives based on risk-adjusted outcomes
Figure 1. Candidate Predictors and Fiited Model ORs
Figure 2. Heterogeneity Effects on Subgroups Calibration

 photo")