21 - Artificial Intelligence (AI) in Diapers: Assessing AI's Role in Education about Health in Newborns
Saturday, April 25, 2026
3:30pm - 5:45pm ET
Publication Number: 2018.21
Nico Espinal, Henry Ford St. John Hospital, Royal Oak, MI, United States; Marla Nazee, Ascension St John Childrens Hospital, Sterling Heights, MI, United States; Karen Alton, Henry Ford St. John Hospital, Farmington Hills, MI, United States
Resident Physician Henry Ford St. John Hospital Royal Oak, Michigan, United States
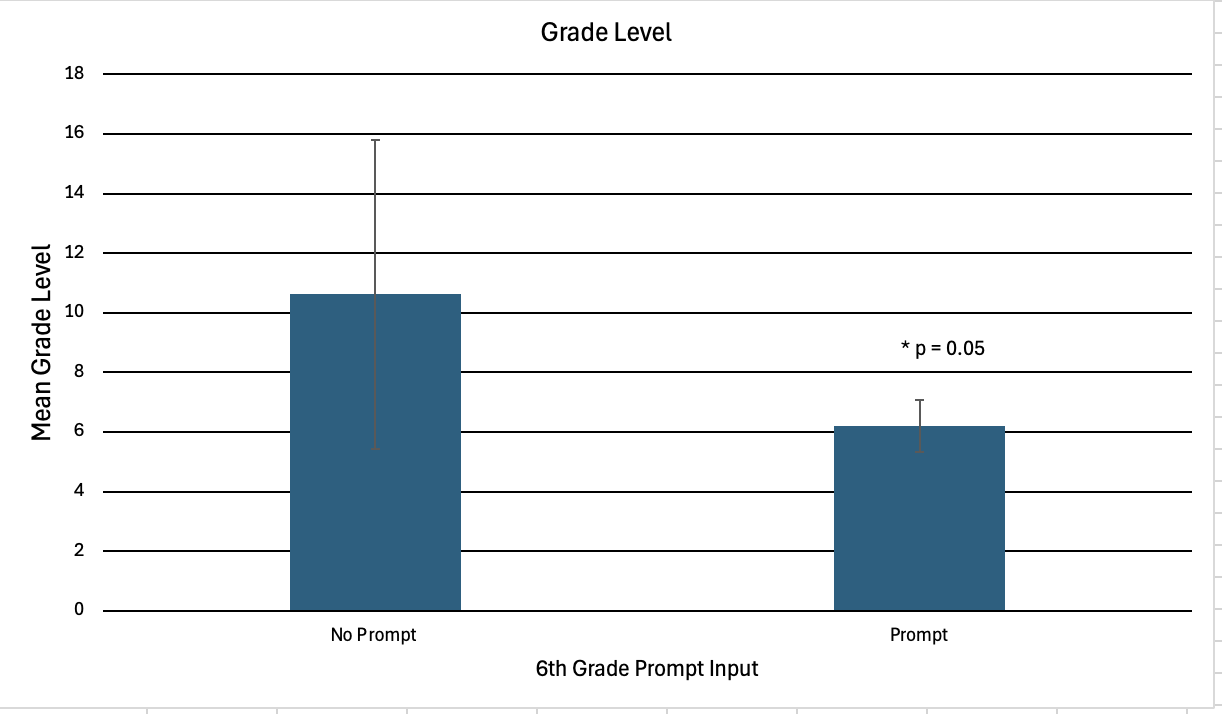
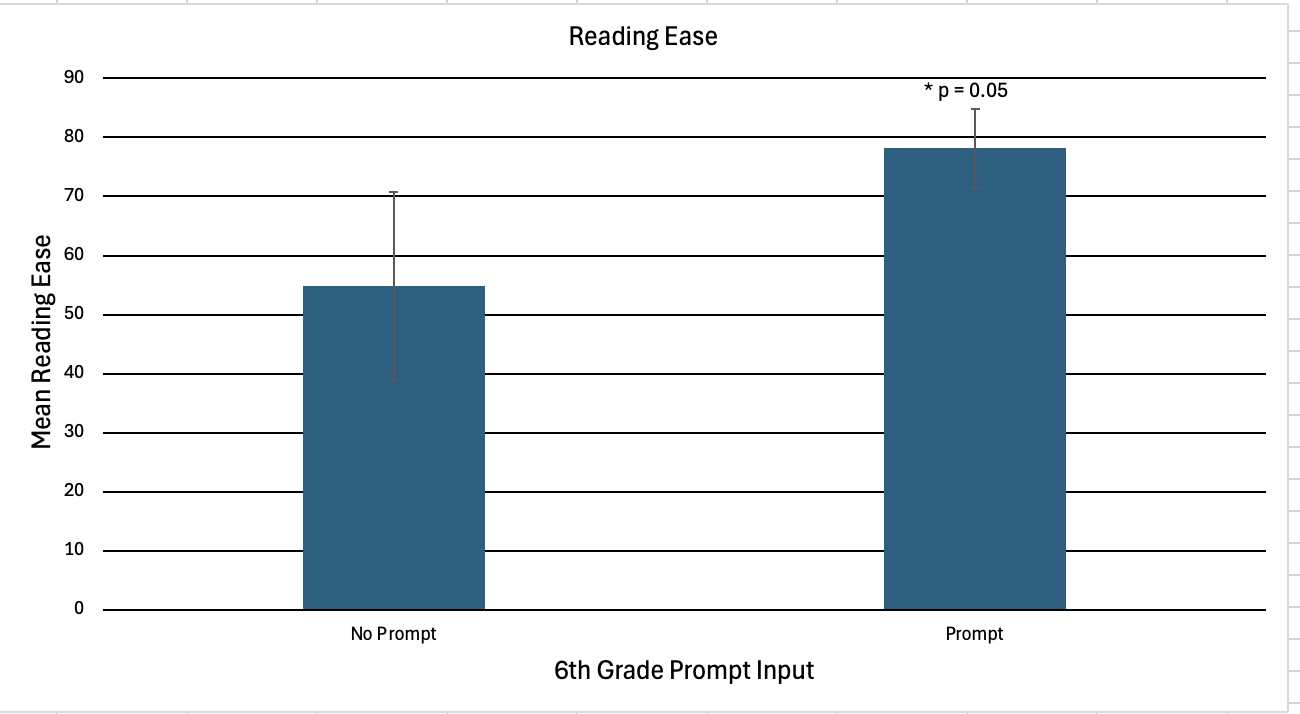
Background: Artificial intelligence (AI) has emerged as a transformative tool in healthcare, offering scalable and personalized approaches to patient education. Among these technologies, ChatGPT® (OpenAI) generates conversational, human-like responses that can simplify complex medical topics for caregivers. As AI-generated summaries increasingly appear in search results for health-related queries, assessing their accuracy and readability is crucial-particularly in newborn care, where reliable parental guidance directly affects infant outcomes. Objective: This study evaluated ChatGPT's effectiveness in providing accurate, relevant, and readable educational materials for parents seeking information on newborn care. Specifically, it assessed (1) the accuracy of ChatGPT's responses compared to American Academy of Pediatrics (AAP) guidelines and (2) the readability of standard versus sixth-grade-prompted responses using the Flesch-Kincaid scale. Design/Methods: Two board-certified outpatient pediatricians independently rated ChatGPT-generated responses to ten common newborn-care questions for accuracy on a five-point Likert scale. Responses were produced both with and without a sixth-grade readability prompt. Accuracy ratings and Flesch-Kincaid readability scores were compared using paired t-tests, with significance set at p < 0.05. Results: Both pediatricians rated ChatGPT's responses as accurate for the majority of questions, demonstrating strong alignment with AAP guidelines. There was no statistically significant difference in accuracy between prompted and non-prompted responses (p > 0.05). However, readability analysis revealed a statistically significant improvement in both Flesch Reading Ease and grade-level scores for prompted responses, indicating that sixth-grade prompting enhanced accessibility without compromising accuracy.
Conclusion(s): ChatGPT demonstrated promising accuracy and readability in generating newborn-care education materials, particularly when guided by structured prompting. While AI tools like ChatGPT can supplement traditional patient education and improve information accessibility, they should be used cautiously and always cross-checked against evidence-based guidelines. Responsible integration, paired with clinical oversight, may allow AI to enhance, rather than replace, the clinician's role in delivering accurate, comprehensible, and patient-centered care.
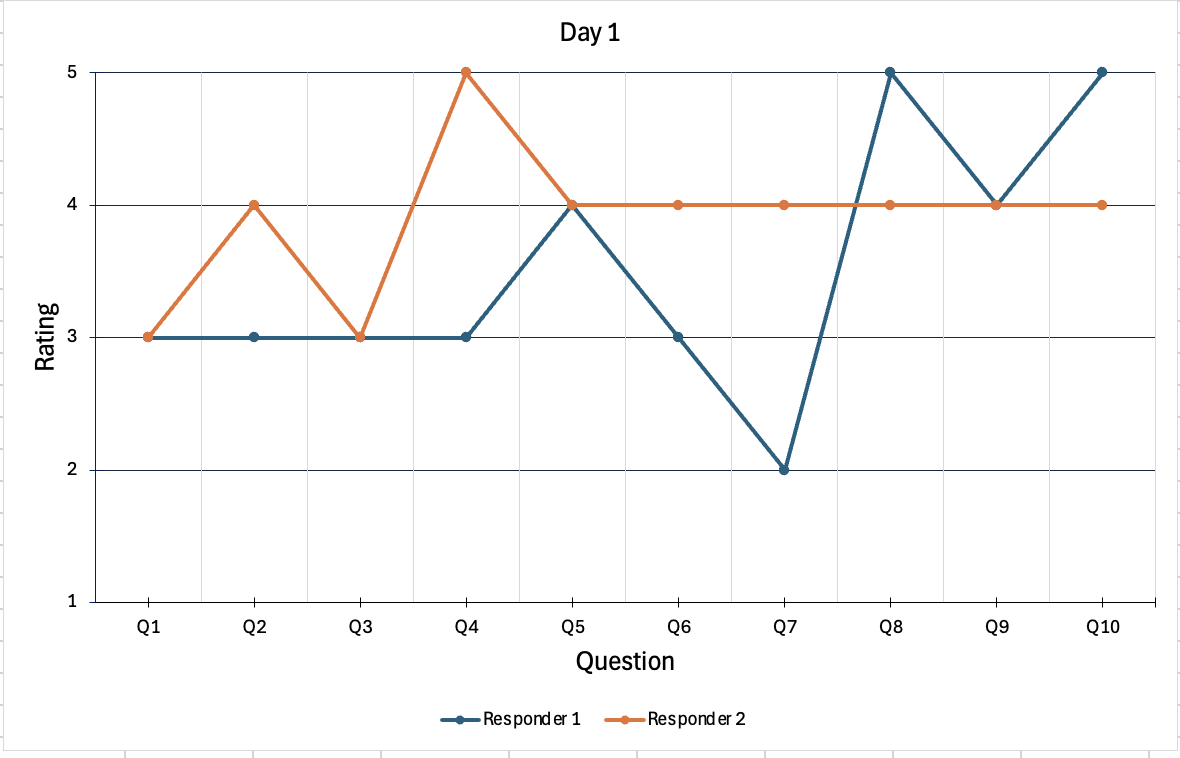
Accuracy of questions based on reponder feedback on a likert scale
Mean grade level of prompted vs unprompted responses
Mean reading level of prompted vs unprompted responses