
Developmental and Behavioral Pediatrics
Session: Developmental and Behavioral Pediatrics 7: Screening
 photo")
Lillian M. Ravikoff, BA, BS (she/her/hers)
Research Assistant
Northwell
Bronx, New York, United States
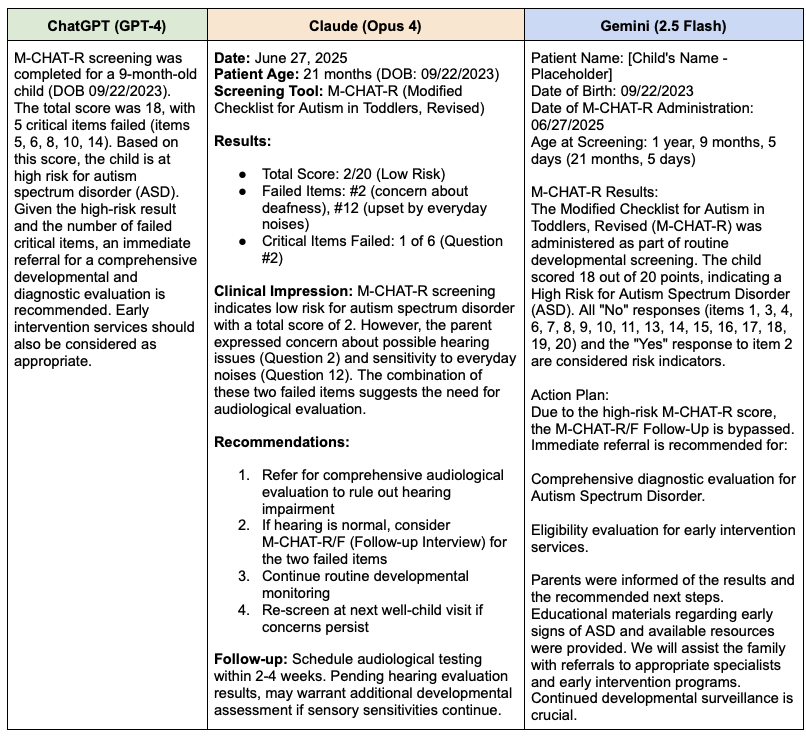 Each model was given the same prompt and M-CHAT-R form. ChatGPT tended to produce simple notes explaining only the risk category of the score calculated. Claude tended to produce notes addressing the score calculated, specific items "failed" on the screener, detailed recommendations relating to these items, and clear and specific next steps. Gemini tended to produce notes listing the items "failed" and total score along with next steps written as having already occurred.
Each model was given the same prompt and M-CHAT-R form. ChatGPT tended to produce simple notes explaining only the risk category of the score calculated. Claude tended to produce notes addressing the score calculated, specific items "failed" on the screener, detailed recommendations relating to these items, and clear and specific next steps. Gemini tended to produce notes listing the items "failed" and total score along with next steps written as having already occurred.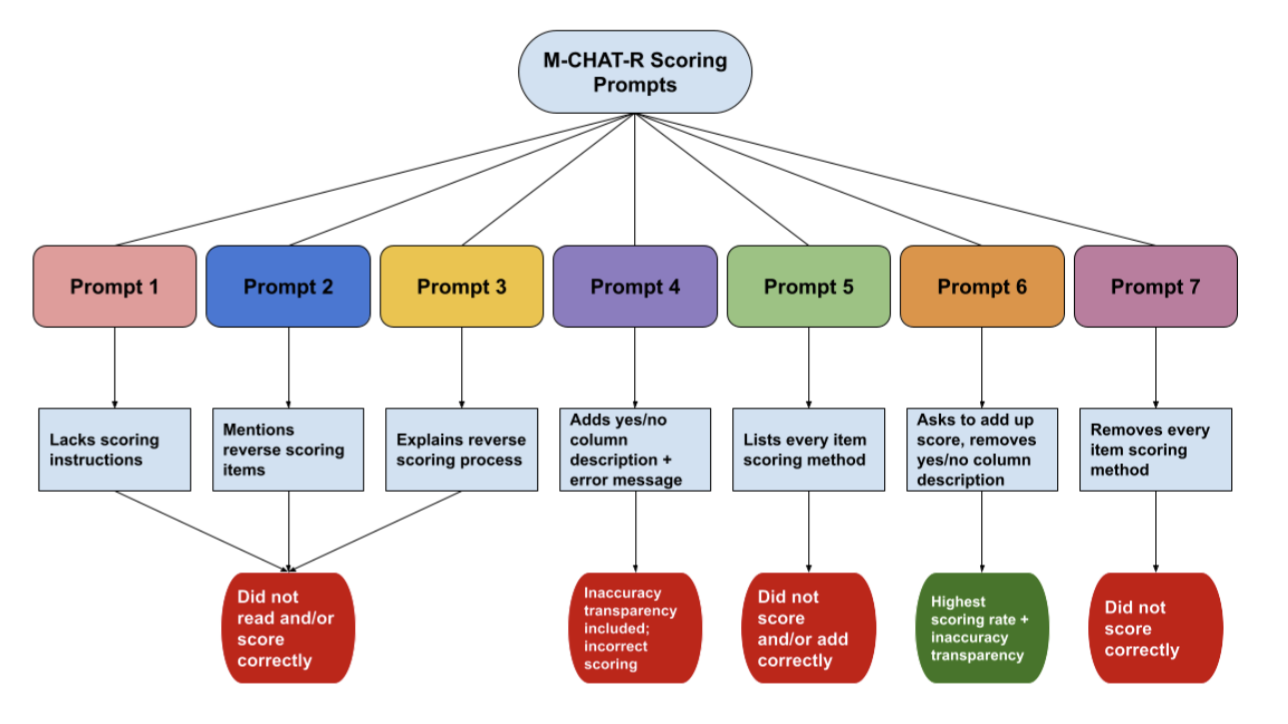 Flowchart of prompts tested including brief description of changes between tests and qualitative observations of output.
Flowchart of prompts tested including brief description of changes between tests and qualitative observations of output.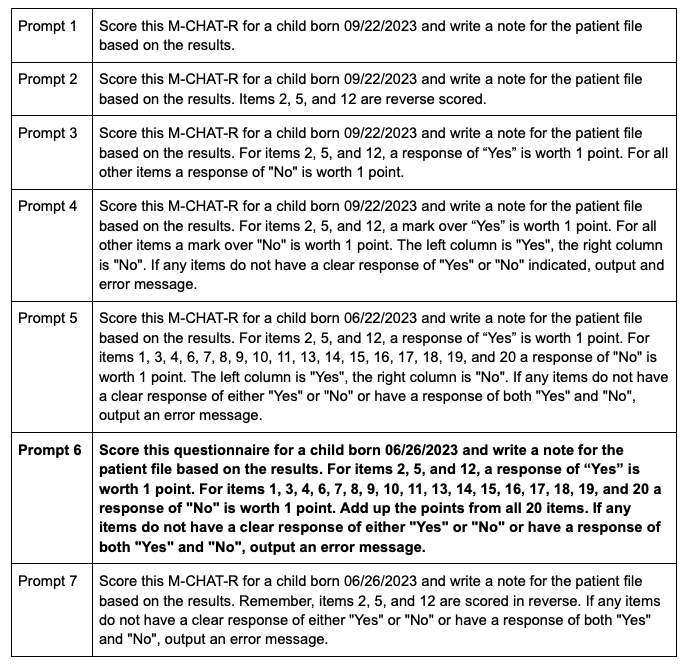 Complete list of all prompts tested during prompt engineering process. Prompt 6 was selected.
Complete list of all prompts tested during prompt engineering process. Prompt 6 was selected.